Architecting the Future of Embedded Finance: A Blueprint for Real-Time Underwriting and Compliance in the 2026 Indian Ecosystem
Step 1: The Technical Blog
High-Level Design for a Zero-Latency, DPDP-Compliant Credit Line on UPI Underwriting Engine
The Indian financial technology ecosystem in 2026 operates under a strict paradigm defined by three intersecting vectors: the maturation of the Account Aggregator (AA) framework, the uncompromising enforcement of the Digital Personal Data Protection (DPDP) Act of 2023, and the sub-second latency demands of the Credit Line on UPI (CLOU) initiative. The era of T+2 days for Small and Medium Enterprise (SME) loan origination has been rendered entirely obsolete. Lenders are now required to execute cash-flow-based underwriting using unstructured bank statement data in real-time, without violating the “purpose limitation” and “secure data erasure” mandates enforced by the Data Protection Board of India.
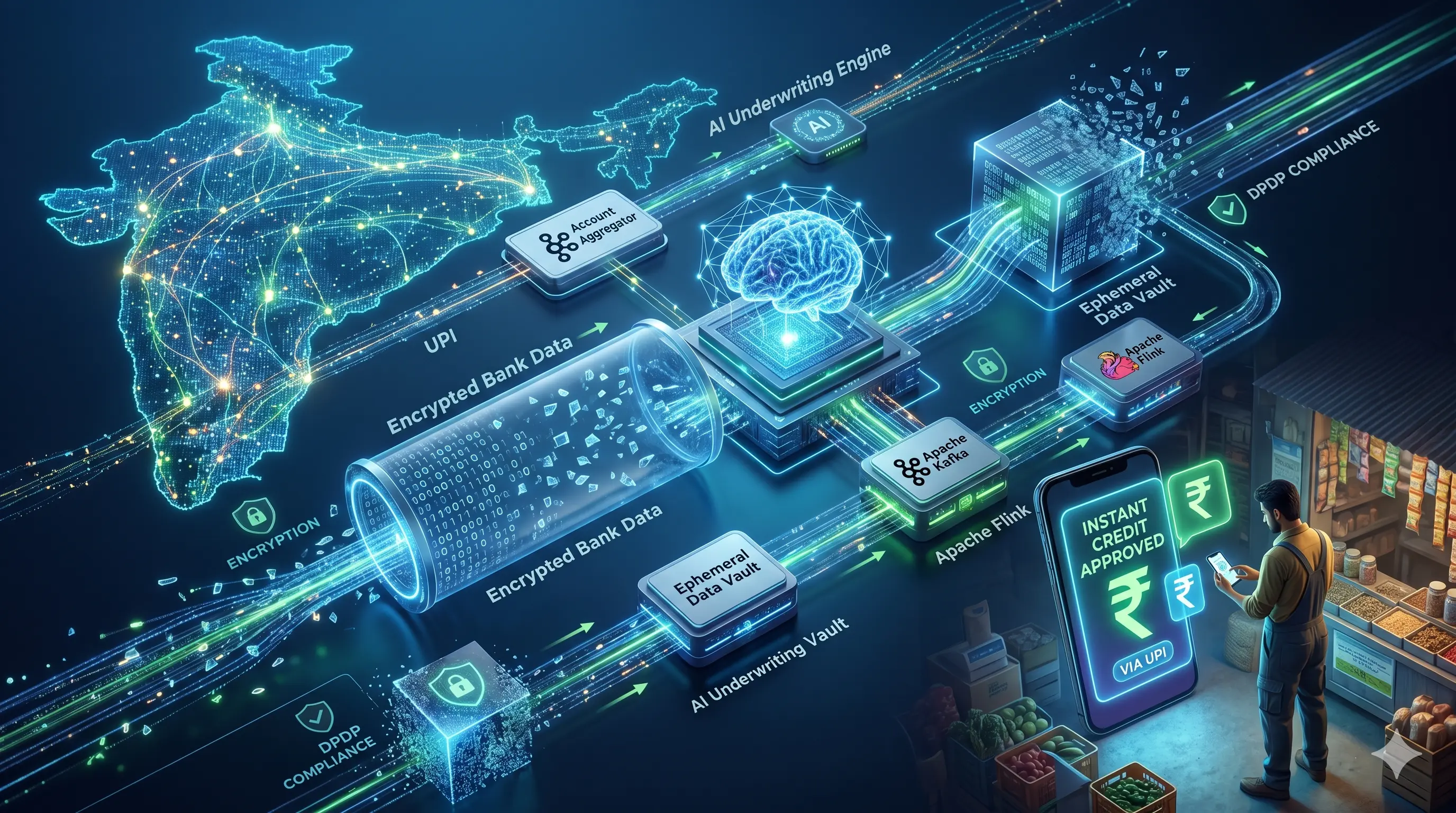
To resolve this trilemma, a modern, event-driven architecture is required. This technical analysis details the High-Level Design (HLD) of a streaming artificial intelligence underwriting engine that integrates with ReBIT v2.0.0 API specifications, processes financial data via Apache Kafka and Apache Flink, and routes regulatory logs through an Ephemeral Data Vault.
1. The Interoperable Gateway: ReBIT v2.0.0 API Integration
The Reserve Bank Information Technology Pvt Ltd (ReBIT) v2.0.0 specifications overhauled the AA ecosystem by introducing mandatory header changes, strict deprecation of legacy v1.1.x protocols, and optimized streaming data fetches. The architecture proposed herein utilizes a highly concurrent, asynchronous API gateway to manage Financial Information User (FIU) operations efficiently, mitigating the 14-to-18-second data retrieval latency historically associated with legacy implementations.
When an SME user initiates a credit request, the system triggers the /Consent API. The payload is cryptographically secured to prevent tampering and ensure non-repudiation. The implementation requires the x-jws-signature in the header, which is a detached JSON Web Signature (JWS) of the request body.
JSON
{ "ver": "2.0.0", "timestamp": "2026-05-09T15:23:55.384Z", "txnid": "644d2aff-e43b-4bb9-9047-498cbb9896d2", "ConsentDetail": { "consentStart": "2026-05-09T15:23:55.384Z", "consentExpiry": "2026-05-10T15:23:55.384Z", "consentMode": "STORE", "fetchType": "ONETIME", "consentTypes":, "fiTypes":, "DataConsumer": { "id": "fiu-embedded-credit-prod", "type": "FIU" }, "Purpose": { "code": "101", "refUri": "https://api.rebit.org.in/aa/purpose/101.xml", "text": "Loan Underwriting" }, "FIDataRange": { "from": "2025-11-09T00:00:00.000Z", "to": "2026-05-09T00:00:00.000Z" } } }
Upon user approval via the AA application, the FIU receives a callback. Rather than relying on synchronous polling, which severely degrades system throughput during peak load, the /FI/request is dispatched, and a Webhook API (/FI/Notification) listens for the READY status from the Financial Information Provider (FIP). Once the combined data session status registers as COMPLETED, the encrypted payload is fetched via the /FI/fetch endpoint and pushed directly into the event-streaming backbone.
2. Streaming AI Cashflow Parser: The Kafka and Flink Pipeline
The core technical bottleneck in the AA ecosystem involves parsing up to twelve months of unstructured, highly fragmented bank statement data—often spanning thousands of rows of transactional data across multiple accounts—in real-time. Monolithic architectures that load this data into relational databases before executing batch-based credit models fail to meet the National Payments Corporation of India’s (NPCI) strict API response time limits for the CLOU framework. Traditional Request-Response paradigms, particularly those relying on Python’s Global Interpreter Lock (GIL) and Celery task queues, introduce severe greenlet contention and starve parallel processing capabilities.
To achieve a P99 latency of under 2.0 seconds, the architecture implements an event-driven processing core utilizing stream processing principles.
A. High-Throughput Ingestion via Apache Kafka
The decrypted JSON/XML bank statement payload is published to an Apache Kafka topic, partitioned by customerId. Kafka serves as a high-throughput, fault-tolerant buffer that absorbs traffic spikes during peak B2B transaction hours. The distributed commit log ensures exactly-once semantics, preventing the double-counting of revenue or liabilities, which is critical for accurate credit assessment.
B. Real-Time Stream Processing via Apache Flink Apache Flink consumes the Kafka stream. Flink is utilized for its stateful processing capabilities, sub-millisecond execution times, and robust backpressure mechanisms that prevent downstream services from being overwhelmed during traffic surges. A custom Flink application parses the transactional strings, categorizing them via localized models into specific vectors: recurring B2B Fast-Moving Consumer Goods (FMCG) receipts, utility payments, outward vendor transfers, and critical risk markers such as inward cheque bounces.
C. In-Memory Dynamic Underwriting Flink executes a tumbling window aggregation to calculate average monthly revenue, debt-to-income ratios, and working capital gaps over the extracted period. This structured data is fed into a lightweight Gradient-Boosted Decision Tree (GBDT) model loaded directly into the Flink runtime memory. By embedding the model inference directly within the stream processing layer, the architecture eliminates the latency inherent in external API calls to isolated machine learning microservices, calculating the optimal borrowing limit dynamically and deterministically.
3. The Ephemeral Data Vault: Enforcing DPDP Rule 8
The DPDP Act Rules of 2025 established severe penalties—ranging up to ₹250 crore—for the failure to protect personal data or adhere to purpose limitations. Furthermore, Rule 8 mandates the strict erasure of personal data once the specified purpose is fulfilled, requiring deletion if the individual has not interacted with the service for a specified period, and mandating a 48-hour warning prior to erasure. Storing twelve months of a user’s transactional data post-underwriting represents an unacceptable regulatory and cybersecurity risk profile.
The system addresses this through a “Zero-Retention” Ephemeral Data Vault architecture.
- Memory-Bound Processing: Raw bank statements fetched from the FIP are never written to persistent disk storage (e.g., Amazon S3 buckets or PostgreSQL tables). They reside entirely in transient, encrypted memory during the Flink processing phase, isolated via strict network access controls and Zero Trust boundaries.
- Cryptographic Tokenization: Any Personally Identifiable Information (PII) required for regulatory matching (e.g., account numbers, PAN) is tokenized at the gateway level using a Hardware Security Module (HSM) cluster before entering the analytical pipeline. The HSM layer generates and protects root keys, orchestrating key lifecycle management and automated rotation.
- Automated Erasure Hooks: The exact millisecond the Flink underwriting engine outputs a binary decision (Approved/Declined) and a calculated credit limit, an automated hook triggers the immediate purging of the raw transactional stream from memory.
- Immutable Compliance Logging: To satisfy audit requirements under the RBI Digital Lending Directions 2025, the system retains only the derived, non-PII variables (e.g., “Average Monthly Cash Flow = ₹5,00,000”, “Bounce Rate = 0.5%”), the decision logic hash, and the cryptographic proof of data deletion. This ensures compliance with DPDP Rule 8 while maintaining the continuous auditability required by the RBI.
4. Automated FLDG and CIMS Reporting
Under the RBI’s updated digital lending framework, Regulated Entities (REs) are mandated to report all Digital Lending Apps (DLAs) to the Centralised Information Management System (CIMS) portal. Furthermore, strict parameters govern Default Loss Guarantee (DLG/FLDG) arrangements, which are strictly capped at a maximum 5% portfolio exposure to ensure lenders maintain adequate “skin in the game”.
The architecture integrates a dedicated Element-Based Reporting (EBR) microservice that subscribes to the final underwriting decision topic. For every originated loan, this service updates the FLDG ledger in real-time, ensuring that portfolio limits are programmatically enforced before the loan is formally sanctioned. If a new loan pushes the RE-LSP (Lending Service Provider) partnership past the 5% DLG cap, the system invokes an automated circuit breaker, degrading gracefully by routing the loan request to a secondary RE partner within the multi-lender LSP framework.
This microservice translates the origination data into the specific extensible Business Reporting Language (XBRL) taxonomy required by the RBI and automatically transmits the required KFS (Key Fact Statement) and digitally signed contracts to the borrower via an asynchronous SMS/Email worker, satisfying Clause 8 of the 2025 Directions.
By decoupling data ingestion from persistent storage and leveraging high-throughput streaming analytics, the proposed architecture satisfies the rigorous demands of the 2026 financial ecosystem. It replaces the cognitive load and multi-day latency of traditional loan applications with an instant, DPDP-compliant engine capable of deploying capital securely via UPI in under three seconds.


